2018-12 SQLCom Meet Up
Друзья, мы рады сообщить вам, что скоро состоится Meet Up нашего сообщества.
На этот раз мы встретимся в Санкт-Петербурге, в отеле VOX (скидка на номер 15% по промокоду SQLCOM)
Регистрация
i. Часть первая Суббота (1 декабря)
| Время | Тема |
|---|---|
| 17:00 - 17:15 | Сбор в отеле VOX |
| 17:15 - 19:00 | Едем любоваться раскрасивейшим Петербургом на автобусе с гидом |
| 19:00 — 20:30 | Возвращаемся в отель, ужинаем |
| 20:30 | Stand Up & Drink Up! |
Меню — https://www.restorating.ru/spb/catalogue/hacho-i-puri/menu/#content
Средний чек (еда) — 700-1000 р.
Средний чек (еда+алкоголь) — 1500 р.
ii. Часть вторая Воскресенье (2 декабря)
| Время | Тема |
|---|---|
| 10:00 - 11:00 | Практическое применение секционирования в SQL Server |
| 11:00 - 11:15 | Кофе ☕ брейк |
| 11:15 - 12:15 | Решение задач машинного обучения на платформе Microsoft SQL Server 2019 |
| 12:15 — 12:30 | Кофе ☕ брейк |
| 12:30 — 13:30 | Построение DWH на стеке MS SQL 2016 |
| 13:30 — 14:30 | 🍲 Обед 🥗 |
| 14:30 — 15:30 | Intelligent Query Processing в SQL Server |
| 15:30 — 15:45 | Кофе ☕ брейк |
| 15:45 — 16:45 | Benchmarkinq TSQL and SQL Server Toolkit |
Фотоотчет



Доклады
Дмитрий Пилюгин

Intelligent Query Processing в SQL Server
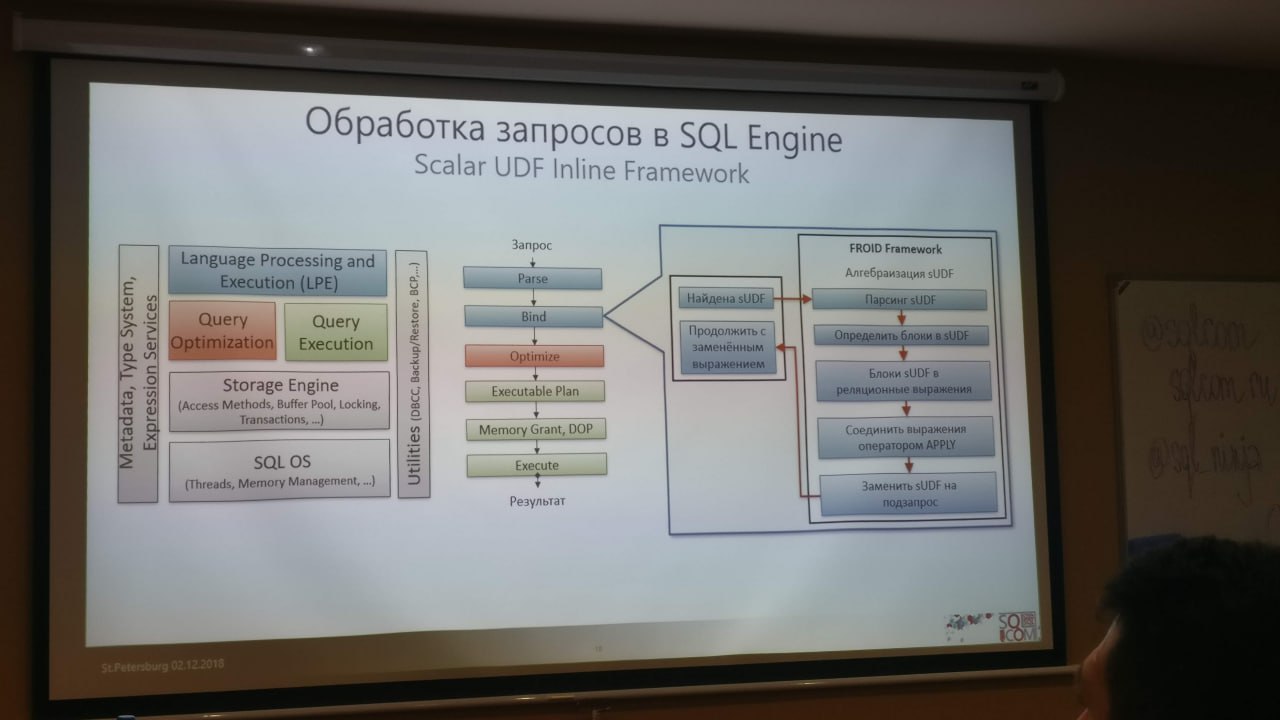
Производительность запросов, один из самых важных аспектов работы с базами данных. Однако все мы сталкивались с ситуацией, когда запросы работают медленно и неэффективно. Причины проблем с производительностью могут быть разные, но часть из этих проблем позволяет решить «Умная» обработка запросов (Intelligent Query Processing) в SQL Server 2019.В настоящее время Intelligent Query Processing включает в себя: — Адаптивную обработку запросов (Adaptive Query Processing); — Отложенную компиляцию для табличных переменных (Table Variable Deferred Compilation); — Пакетный режим обработки над данными в Rowstore формате (Batch Mode Over Rowstore); — Приблизительная обработка запросов (Approximate Query Processing). В докладе мы рассмотрим как использовать эти функции, и в каких случаях они могут увеличить производительность.
О себе
Дмитрий работает руководителем группы баз данных в компании Mediasope, до этого занимался разработкой корпоративных информационных систем на платформе Microsoft SQL Server. Ведет технические блоги www.queryprocessor.ru и www.queryprocessor.com посвященные SQL Server, периодически выступает на различных конференциях, а также участвует в профессиональных SQL Server сообществах, консультируя в области оптимизации запросов. Является обладателем статуса Microsoft Most Valuable Professional по направлению Data Platform.
Константин Таранов

Benchmarkinq TSQL and SQL Server Toolkit
Тестирование скорости работы TSQL кода, лучшие практики по написанию хранимых процедур, бесплатные и платные решения для работы с SQL Server.
О себе
Разработчик и администратор баз данных с более чем 10-ти летним стажем, эксперт по работе с Microsoft SQL Server, Oracle, MySQL.
Михаил Комаров

Решение задач машинного обучения на платформе Microsoft SQL Server
Мы рассмотрим компоненты Microsoft SQL Server 2019 связанные с задачами машинного обучения, а также их взаимодействие с базовыми компонентами Microsoft SQL Server 2019.
О себе
Занимается поддержкой существующих и реализацией новых систем, направленных на повышение эффективности работы в корпоративном сегменте. До работы в крупном корпоративном секторе работал тренером по информационным технологиям. Общий опыт работы в сфере ИТ составляет более 20 лет. Из интересов, виртуализация, инфраструктура, анализ данных и машинное обучение. Microsoft MVP с 2011 года.
Кривец Владимир

Построение DWH на стеке MS SQL 2016
Мы рассмотрим подход к проектированию и созданию хранилищ данных на стеке Ms sql server 2016+. Начнем с придумывания верхеуровневой архитектуры и закончим рассмотрением вопросов эффективного хранения данных на физическом уровне. Попутно будем разбирать «плохие практики» при работе с большими данными.
О себе
DWH разработчик. Последние 4 года занимался внедреним DWH для крупных российских компаний — Банки, Телекомы, Производство. Видел очень много плохих практик и много хороших. Готов поделиться своим ИМХОм=)
Сергей Олоноцев

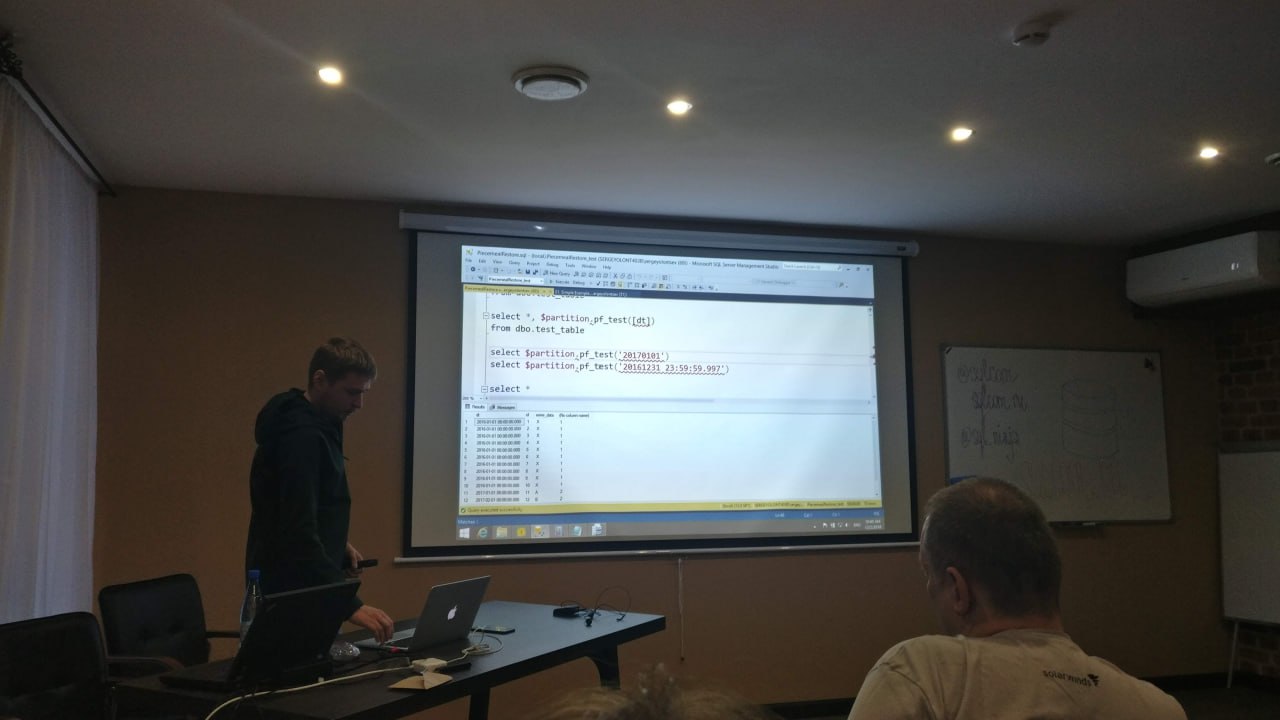
Практическое применение секционирования в SQL Server
Вы уже, наверное, слышали, что секционирование используется, чтобы разбить большие таблицы на более мелкие части, чтобы архивировать старые данные, а свежие поместить на более быструю дисковую подсистему.
Однако, разве это единственный способ использовать его?
- С чего начать, в чем преимущества и недостатки секционирования?
- Как правильно выбрать столбцы, функцию и схему секционирования?
- Как можно использовать секционирование для высоконагруженных проектов?
- Какие подводные камни могут встретиться?
- Что делать, если у вас не Enterprise Edition?
На эти и другие вопросы я отвечу в рамках этой сессии с помощью историй из практики и живых демонстраций.
О себе
Data Platform MVP, SQL Server MCM etc. Работает с SQL Server уже более 13 лет начиная еще с версии 2000. За это время успел побыть и администратором, и разработчиком, и аналитиком. Специализируется на проектировании высоконагруженных баз данных, оптимизации производительности и т.п. В последнее время много работает и с облачными БД и с NoSQL решениями.